First of all, I would like to clarify that this post, like the previous ones, was written without AI. I believe it is important to share authentic feedback and reflections drawn from personal experience.
There is something quite fascinating about the history of computing: technologies change, architectures evolve according to needs… and above all according to buzzwords that follow one another at high speed.
And yet, some mistakes seem to benefit from a remarkable form of immortality. AI will probably not escape this rule.
For months now, AI demonstrations have been multiplying everywhere. Conversational agents are appearing across every domain. “AI-augmented” workflows are becoming omnipresent. POCs are piling up with the collective feeling that we are witnessing a major technological breakthrough.
And it would be absurd to deny that this disruption is real.
But it would be just as dangerous to believe that simply changing the technology is enough to make long-standing structural problems disappear. Because when looking at some of the architectures emerging today, a strange sense of déjà vu sometimes starts to appear.
A feeling that strongly recalls another era: the rise of RPA within organizations.
A technology toward which I have always remained relatively cautious. RPA was pushed with enormous enthusiasm and welcomed as the messiah of augmented productivity. Excitement was everywhere. Automation finally promised to revolutionize organizations. Demonstrators were impressive. Fast ROIs became the new magical argument of management teams.
A robot capable of automatically reproducing human actions on an interface suddenly became the answer to a multitude of business problems.
And for a while, it seemed to work, and the first waves of feedback quickly emerged:
“RPA must be quick to implement.” “ROI must be immediate.” “Finally, we can automate the entire invoicing process.”“We can automate the complete processing of requests.”And above all: “We can avoid modifying the existing information system.”
That last sentence was probably the most important one… or rather the most worrying one.
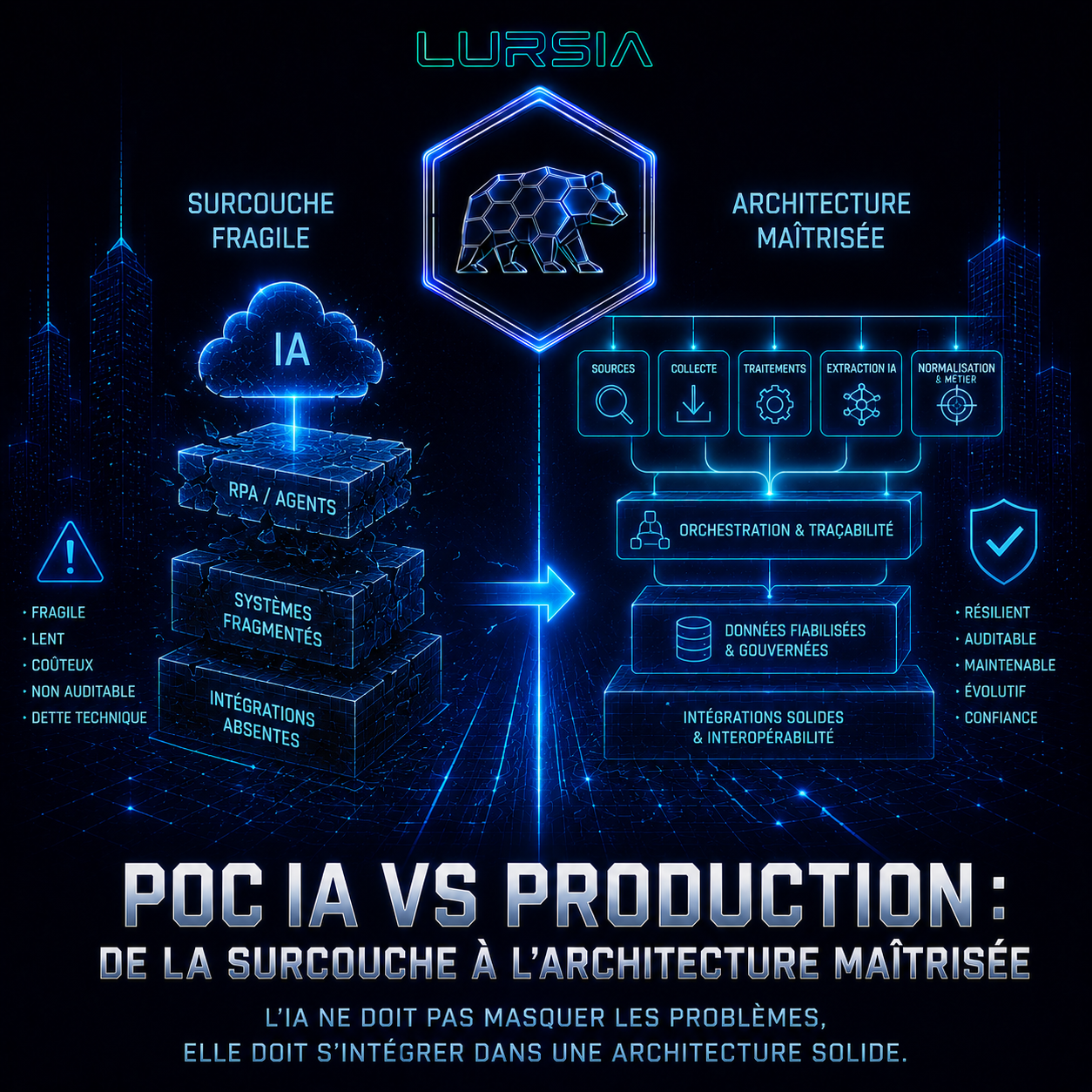
Because behind the theoretical elegance of the technology often hid another reality: RPA mainly acted as an additional layer intended to compensate for the absence of proper integration protocols between systems.
In other words, instead of solving certain structural issues within the information system, organizations added another layer capable of artificially imitating human behavior on top of architectures that themselves remained deeply fragmented and poorly interoperable.
And obviously, it gave the impression that it worked. At least… up to a certain point.
Because a robot clicking on buttons remains fundamentally less robust than an integration designed natively between systems: slower, more fragile, harder to maintain, dependent on interface evolutions… and therefore more costly over time.Every screen change could potentially become an incident. Every evolution of the information system introduced new invisible dependencies. Technical debt did not disappear; it simply changed form.
And this is probably where the parallel with some current AI trajectories becomes interesting.
Because today we are observing a relatively similar phenomenon. Faced with the limitations of existing systems, many organizations are now adding AI layers capable of interpreting inconsistent data, artificially reconnecting flows, reformulating content, filling functional gaps, or temporarily masking certain structural weaknesses of the information system.
And once again, the demonstrations often work extremely well.
But one question probably deserves to be asked honestly:
Are we truly solving problems sustainably… or are we simply building a new abstraction layer on top of architectures that themselves remain poorly mastered, poorly interfaced, and poorly coordinated?
Because AI has this extremely seductive ability to temporarily mask part of the complexity.
An agent can interpret inconsistent data, reconcile different terminologies, navigate across multiple tools thanks to new protocols, or give the impression of compensating for certain structural weaknesses.
All of this artificially creates continuity and fluidity where the system itself does not truly possess them.
The risk appears when these AI layers progressively become structural dependencies of the information system themselves.
This is precisely what we are already beginning to observe. Business logic slowly migrates into non-versioned prompt chains, often strongly coupled to the agents being used. Decisions become harder to audit. Reasoning mechanisms become less explainable. And agentic workflows sometimes end up becoming more complex than the systems they were initially supposed to simplify. At that point, a new form of debt appears.
A debt that is probably even more difficult to govern because it directly impacts the understanding of decisions, auditability, traceability, accountability… and ultimately the organization’s overall trust in its own systems.
And this trust remains today one of the main causes of rejection within organizations.
The problem therefore is not AI itself. The problem appears when AI becomes a permanent substitute for architectural problems that would actually require deeper reflection around data models, exchange protocols, business semantics, governance, or the overall trajectory of the information system.
Because make no mistake: An information system will always eventually present the bill for the shortcuts imposed upon it.
This reflection is precisely what strongly influences certain architectural decisions I regularly make.
While designing an intelligent industrial analysis platform, one very concrete question rapidly emerged: how do you build a chain capable of collecting, consolidating, and securing data coming from a fundamentally chaotic environment?
In our case, the data came from multiple sources: manufacturers, distributors, data providers, APIs, web scraping, emails, document repositories… It also existed in highly heterogeneous forms: PDFs, JSON files, photos, tables, graphs, technical diagrams, regulatory data, supply-chain information… all with extremely variable quality levels.
The traditional temptation would have been to build a “super agent” capable of doing everything: searching for data, navigating systems, understanding documents, extracting information, interpreting results, and directly producing a final business-oriented record.
On paper, the demonstration would probably have looked spectacular.
In reality, it would mostly have produced a system that would be extremely difficult to explain, audit, and maintain.
I therefore deliberately chose another direction: Rather than considering AI as the unique brain of the system, the decision was made to build a true industrial chain around it. The goal was not to create an agent capable of doing everything, but rather to clearly separate responsibilities. Source discovery is isolated from the collection phase itself. The selection of useful links has its own dedicated logic. Content segmentation and area-of-interest detection operate independently from extraction performed by specialized agents. Then come the normalization, cleaning, restructuring, and business attachment phases.
This probably appears less “magical” during a demonstration. However, it completely changes the resilience of the system.
When an extraction produces an inconsistency, we are able to precisely identify the origin of the issue: the source used, the analyzed fragment, the model involved, the exact workflow version, or even the processing stage concerned. Most importantly, we can relaunch only a specific step without replaying the entire processing chain.
And this becomes absolutely fundamental at industrial scale.
Because a POC can easily tolerate approximation. Production environments cannot.
Furthermore, the collected data is stored in its raw form without modification, and a complete lineage has been implemented throughout the entire propagation chain. Some stages effectively rely on agents, while others simply use traditional algorithms that are sometimes more performant and, above all, easier to reproduce reliably.
The architecture therefore remains deliberately hybrid. AI is only used where it provides an actual benefit.
And above all: an AI output should never be considered a final business datum.
Let us take a simple example from obsolescence management. An agent may perfectly extract multiple different obsolescence dates from the same industrial document. It may retrieve product references that are close yet ambiguous. It may detect contradictory information coming from several distributors.
The demonstration then appears impressive: “The model found information.” Yes. But industrially, that is absolutely not enough.
The information must then be normalized, deduplicated, compared, weighted according to source confidence levels, ambiguities must be resolved, interpretation errors detected, and the whole dataset attached to an exploitable business logic.
In other words: AI feeds a production chain. It does not replace the chain itself.
Another important lesson concerns mutualization. In many AI POCs, every user request triggers a complete processing cycle. This works very well… until costs explode and processing becomes redundant. We therefore introduced another logic: dissociating the user request from the actual technical production. If multiple users request the same reference, there is no need to replay the entire document chain, AI calls, and associated processing. The system reuses an existing production whenever relevant. This seems obvious afterward, but it is precisely the kind of mechanism demonstrators often forget… because they are not yet truly facing production constraints.
And this is probably where the real transition from POC to industrialization lies. The moment when we stop building an impressive demonstration and start building a system capable of surviving scale, time, evolutions, incidents, audits, costs, and above all… the teams who will have to maintain all of this five years from now, as well as the users who rely on it daily and must trust it.
Ultimately, a truly mature AI system is not the one that appears the smartest during a demonstration. It is the one that remains understandable, governable, and maintainable once the demonstration is over.